Introduction
Deep convolutional neural networks have been around for a while and have completely revolutionized how we tackle image recognition task in computer vision. When AlexNet came out in 2012 it revolutionized how we use CNN’s as it was the first time we saw an architecture with consecutive Convolutional Layers with significant improvement in training speed and performance. This was achieved by leveraging deeper architecture and GPU accelaration.This 8 layer deep CNN was one of first to have this kind of performance for a largescale image classification.
In the following years we also got a new CNN model called Visual Geometry Group(VGG), the primary objective of this model was to investigate the effect of increasing the depth of CNN on large-scale image recognition task. A 16 weight layer network VGG-16 and a 19 weight layer network VGG-19 were introduced with consisent 3x3 filters all across the network which simplified the network and improved performance.The simplified 3x3 filter structure is still extensively used and popular among researchers.
These architectures demonstrate that deeper networks often perform better. However,this raises an important question:
Does deeper always mean better?
When we look at it, adding more layer seem advantageous, more depth more complex features the model understands. Why stop at 16 layers or 19 layers? can’t we add more? ofcourse the model will have more parameters to learn and might be computationally expensive,but the tradeoff wouldn’t be so bad, so why not?
Why is it not OK to just add more layers?
Adding more layers introduces challenges beyond computational cost,such as gradient vanishing and degradation problems,as discussed in the ResNet paper titled Deep Residual Learning for Image Recognition
1) Vanishing/Exploding gradients
-
Vanishing Gradient : In deep networks,repeated multiplication of small values(activation function derivatives) causes gradients to shrink exponentially. This slows down learning and makes convergence difficult
-
Exploding Gradient : When values become too large due to high-weight values, gradients explode,making training unstable.
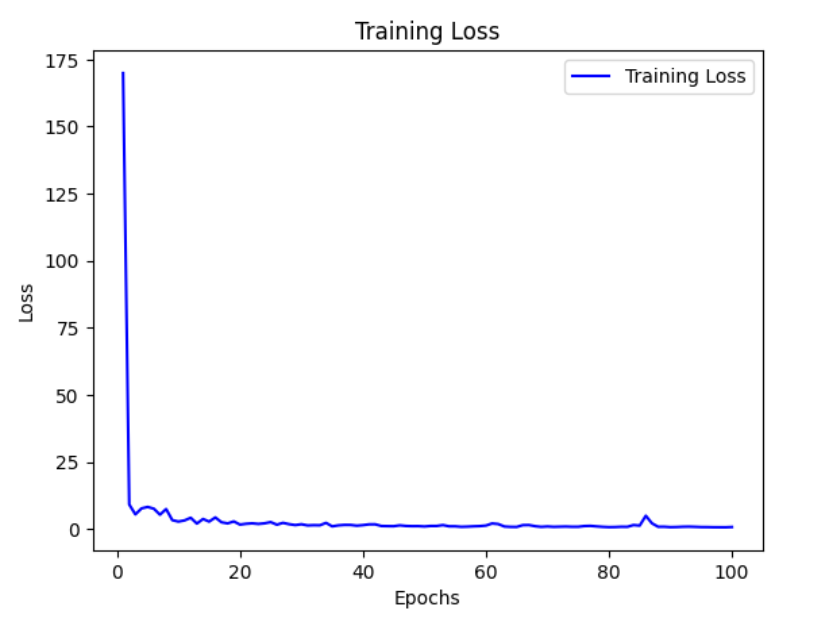
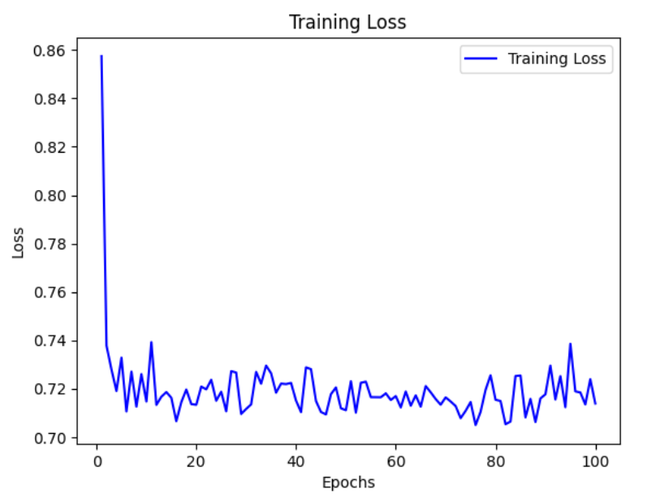
This problem has been largely addressed by applying various techniques like normalized initialization and intermediate normalization layers(Batch Normalization)
2) Degradation Problem
As we stack more and more of the convolutional or non linear layers we execpt the accuracy of the model to increase as well but, the accuracy saturates then starts to degrade after a certain point and it is not caused by overfitting and adding more layers to that causes the error% to increase as well
Example Lets say we have a hypothetical task at hand of classifying image.we build a simple shallow CNN network.
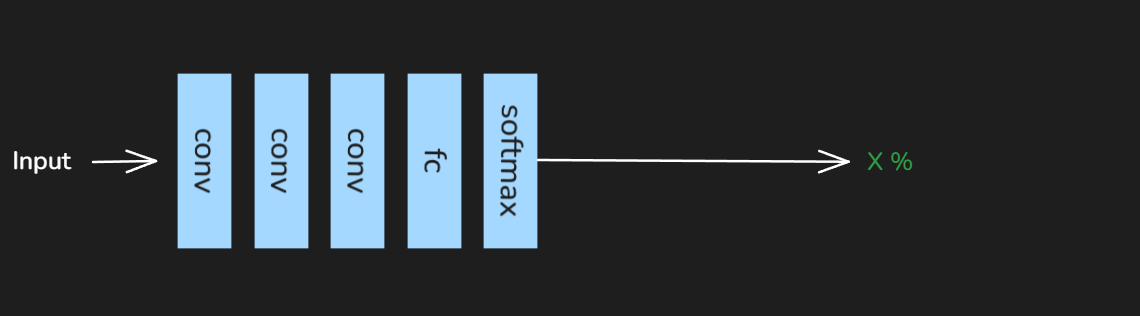
We train this CNN for a certain task and achieve an accuracy of X%, now we will take this shallow model and create it’s deeper counterpart with additional Convolutional layer.
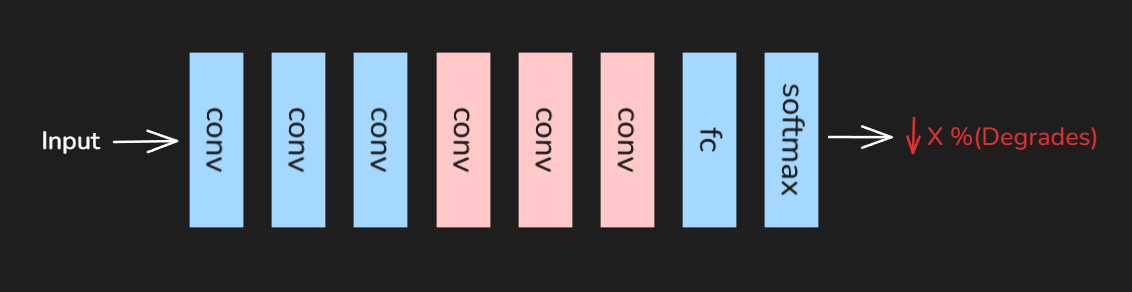
With the addition of covolutional layers to the existing shallow model(base) we find a degradation in accuracy as talked about earlier.Now lets build the same network but with identity layers instead of the convolutional layer.
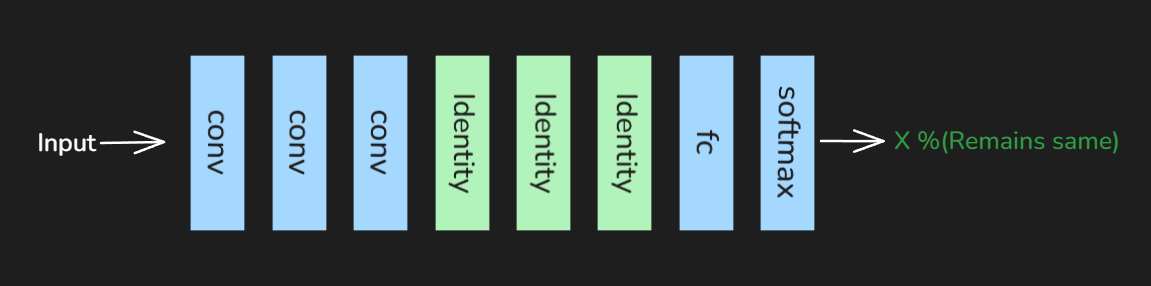
When identity layers are added to the shallow(base)model we find that accuracy remains the same despite the model being deeper than before. Note : Identity layers pass the output as it is without applying any transformation.
What do we learn from this?
-
The current optimization methods struggle because stacking many non-linear layers(like convolution) makes it difficult for the model to preserve the original input-output relationship,or identity mapping.This is what causes the degradation problem in deep networks.
-
Otherwise,the accuracy of a deeper network should have been atleast the same as shallower(base) one.It shouldn’t have degraded
The Solution- Residual Learning
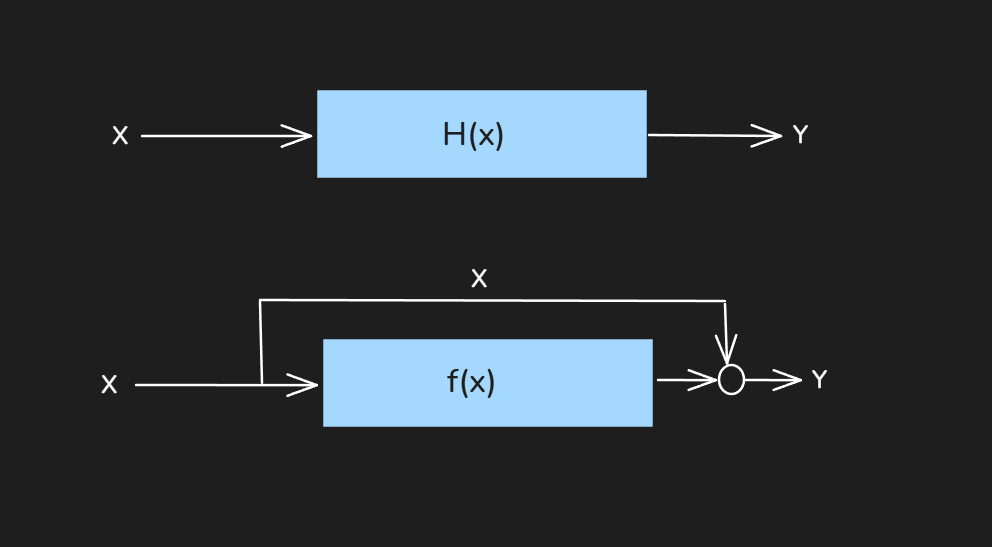
Above is the a diagram for Residual Learning where H(x) is the true mapping function we want to learn, Lets define a function f(x) and learn it instead of H(x)
Residual Block
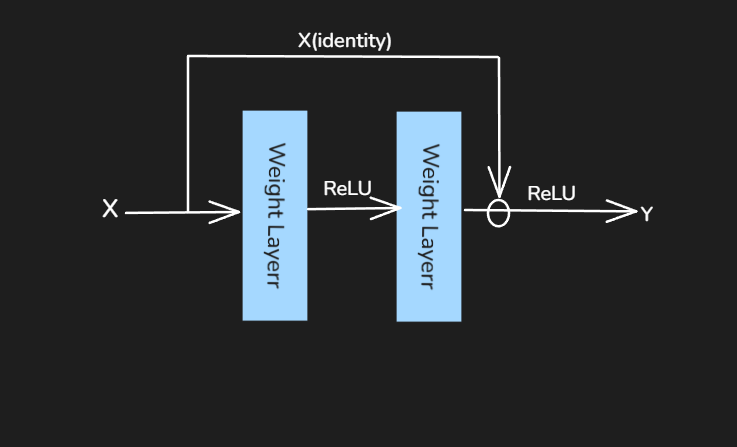
Residual architecture adds explicit identity connections throughout the network ensuring the original input(identity) is passed forward even if residual block learns nothing new.This prevents deeper network from suffering degradation. At the very least, they can mimic the shallower model by preserving identity mappings
So,in actual practice we aren’t skipping anything but passing the original input along with transformed input(convoluted) through the network
Code Implementation of a Residual Block
import torch
import torch.nn as nn
class ResidualBlock(nn.Module):
def __init__(self, in_channels):
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, in_channels, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(in_channels)
self.conv2 = nn.Conv2d(in_channels, in_channels, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(in_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
identity = x # Identity connection
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += identity # Adding input (skip connection)
out = self.relu(out)
return out
Lastly, these identity connections introduce no new parameters to the network architecture,hence it will not add any computational burden.
Residual connections enable deep networks to learn effectively without performance degradation. By preserving identity mappings,ResNets solve vansihing gradients and allow for much deeper architecture. Today,ResNets are widely used in computer vision task and their principles continue to influence newer architectures like Transformer models in deep learning.
References
-
He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770-778. Link
-
GeeksforGeeks. (2023). Vanishing and Exploding Gradients. Link
-
Simonyan, K., & Zisserman, A. (2014). Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations (ICLR). Link
-
Original ResNet paper - Deep Residual Learning for Image Recognition | AISC
YouTube Video -
AlexNet Paper - ImageNet Classification with Deep Convolutional Neural Networks
Paper (NeurIPS 2012)